
新智元报道
编辑:元宇
【新智元导读】麻省理工学院最新研究预示着人类距离能够自主学习的AI又迈出了关键一步。该研究推出了一种全新的自适应大模型框架「SEAL」,让模型从「被动学习者」变为「主动进化者」。
人类距离能够自主学习的AI又迈出了关键一步!
GPT-6是否有望成为第一个具备自主学习能力的大模型?
论文地址:https://arxiv.org/pdf/2506.10943
近日,麻省理工学院(MIT)提出了一种「自适应大语言模型(SEAL)」的框架,使大模型能够具备自我调整与持续优化等能力。
网友VraserX在推荐这篇论文时,称未来发布的GPT-6可能不仅更聪明,而且它还可能「活着」(在计算意义上)。
SEAL架构可以让模型实时从新数据中学习、自我修复退化的知识、在多次会话之间形成持久的记忆……
所以如果GPT-6整合了SEAL这些能力,它将成为一个能随时适应世界变化的模型,一个每天都在变得更好的系统。
这可能标志着自主学习AI的诞生,宣告冻结权重时代的终结。

社交媒体资料显示,该论文作者之一的Ekin Akyürek在OpenAI工作,印证了网友VraserX关于「该论文部分作者现在在OpenAI工作的说法」。
这意味着GPT-6未来有可能成为首批采用SEAL框架的前沿大模型之一。
「自我编辑」
让大模型产生「自适应」能力
大模型的功能虽然强大,但这种强大往往是「静态」的,无法根据新任务、新知识或新样本而自动更新。
在SEAL框架下,当大模型遇到一个新输入时,它会进行一次自我编辑(self-edit),生成一段文本,内容可能是怎样重组已有信息、优化超参数,或调用什么工具来增强数据、更新模型。
然后,通过监督式微调(SFT),这些「自我编辑」会带来持久的权重更新,从而让模型具备长期适应能力。
为了训练模型这种「自我编辑」能力,研究人员用强化学习(RL)构建了一个闭环系统:
模型更新后在下游任务中的表现,会被当作奖励信号,改进其后续的「自我编辑」策略。
与以往那些额外加适配模块或辅助网络的方法不同,SEAL直接让模型用自己的生成结果来控制它的学习方式。
这一机制使模型摆脱了以往「填鸭教育」的模式,让它更像一个主动学习者。

为了改善大模型的适应性,研究人员主张赋予LLM在面对新输入时生成自己的训练数据与微调指令的能力。
具体来说,是通过强化学习算法,训练 LLM 生成「自我编辑」(self-edits)——以自然语言指令的形式,指定用于更新模型权重的数据,并可选地给出优化超参数(如图 1)。
研究人员将这种具备「自我编辑」能力的模型称为自适应 LLM(SEAL)。
通过知识整合、少样本学习任务来验证SEAL的效果,研究人员发现SEAL可以让大模型具备自我适应的潜力,朝着自我进化的方向前进。
与SEAL相关的研究
1. 合成数据
合成数据在训练大模型时越来越常见,SEAL也是在这条思路上发展起来的。
但不同的是,以往的生成策略大多依赖人工调参或固定规则,而SEAL使用强化学习来自动优化生成策略,让模型能够生成在后续训练中真正可以提升下游任务表现的数据。
2. 知识整合
近来的多项工作尝试通过权重更新来修改或注入事实性知识,SEAL主张通过上下文来生成额外的微调数据,并在此基础上通过强化学习让模型学会生成更优的微调数据。
3. 测试时训练
「测试时训练」(Test-Time Training, TTT)指的是模型在推理时根据输入动态更新部分权重,从而适应新任务。
研究发现,将TTT与上下文学习结合,可以在小样本条件下表现更好。
SEAL的内部优化过程可以看作一种改进版的 TTT:它多次生成并更新权重,奖励那些带来最大性能提升的数据生成策略。
4. 强化学习
强化学习在提升大语言模型性能方面已被证明非常有效。
SEAL的创新之处在于它不是用RL来优化最终答案,而是用来训练模型如何生成那些能用于自我更新的数据。
SEAL 的核心思想是「元学习」——也就是让模型学会如何更好地学习,其优势在于直接利用模型已有的生成能力来决定参数更新方式,从而具备更强的通用性。
5. 自我提升
近年来,许多研究开始探索模型如何自我提升。
比如,RLAIF 或自奖励语言模型让模型自己评估并奖励自己的输出,从而改进表现。也有方法通过模型的置信度或多数投票来指导强化学习。
但这些方法往往受限于模型当前的自我评估能力。
SEAL的做法不同:它把「自我提升」看作与外部数据交互的过程。
通过强化学习,SEAL学会如何最有效地利用这些外部数据,真正实现自我改进。
不直接教模型做任务
而是教它怎样更有效地学习
在SEAL中,模型会根据输入上下文(例如一段知识或几个示例)生成一段合成数据,这段数据就叫「自我编辑」,然后模型再用这段数据微调自己。
整个生成过程通过强化学习训练而来,随着训练推进,它就逐渐学会生成更有用的编辑。
因此,SEAL可以被解释为包含两层循环的算法:
从这点来看,SEAL是一种元学习方法:它不是直接教模型做任务,而是教模型怎样更有效地学习。
研究人员在知识整合与少样本学习两个领域对SEAL能力进行验证。
知识整合

实例的目标是高效地将段落中提供的信息整合到模型权重中。
图2显示了SEAL在知识整合任务中的工作流程,包括Passage(输入段落)、Self-Edit(自我编辑)、Evaluation(评估)。
少样本学习

图3显示了SEAL在少样本学习任务中的工作原理,包括Few-Shot Examples(少样本示例)、Self-Edit(自我编辑)阶段、SFT(监督微调)、Evaluation(评估)。
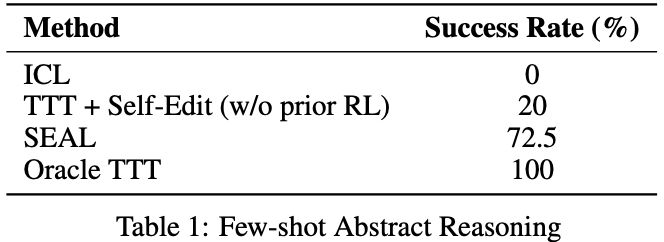
在该项实例中,研究人员通过Llama-3.2-1B-Instruct 进行实验,并与ICL(上下文学习)、TTT + 自我编辑、Oracle TTT等基线进行对比,结果如表1所示:
SEAL显著提升了适配成功率达到了72.5%,但其表现仍低于Oracle TTT,说明仍有改进空间。
据预测,到了2028年,前沿大模型将在所有公开可用的人类生成文本上完成训练。
那时大模型的进步就不再依赖更多人类数据,而要靠自己创造新的学习材料——也就是要学会自身生成、提炼、改进知识。
在这样的趋势下,SEAL展示了一种新的可能:
大模型在预训练后可以通过生成自己的合成自我编辑数据,并以轻量的权重更新来应用它们,使模型可以自主整合新知识、适应新任务。
研究人员希望将能SEAL扩展到更广泛的领域——包括预训练、持续学习和智能体系统,最终让大模型可以在一个数据有限的世界中,真正实现自我学习与自我成长。
虽然在测试中,SEAL仍会出现「灾难性遗忘」的问题,还存在着诸多局限,但SEAL的提出仍为未来前沿大模型实现自主学习、自进化提供了一条值得期待的新路径。
也许未来在GPT-6上,我们就能看到这种自主学习的能力。
参考资料:
https://www.wired.com/story/this-ai-model-never-stops-learning/%20
https://arxiv.org/abs/2506.10943

